
目錄
引言
Gemini 近期表現波動,API Key 與網頁版都頻傳故障,但正在此關鍵時刻,Google 發布了最新模型:Gemini 3.1 Flash-Lite。在企業 AI 應用場景中,並非每項任務都需要博士級科學運算(如 Pro 或 Deep Think),企業更常需要的是一個反應靈敏、隨處可用、成本極低的「數位助手」。Gemini 3.1 Flash-Lite 正為此需求而生——專門承載海量、高頻率的實務工作。
核心優勢一覽
- 成本領先市場:每百萬(1M)Input Token 僅 $0.25,打破企業大規模部署的成本天花板
- 速度飆升突破:首次回應速度(TTFT)較 2.5 Flash 快 2.5 倍,輸出速度增長 45%
- 性能無損縮減:Elo 分數達 1432,MMMU Pro 多模態測試取得 76.8%,推理實力甚至超越前代標準版
- 靈活思考配置:內建 Thinking Levels(思考層級)控制,開發者可自由調度「快速反應」與「深度推理」
定價優勢:市場最低成本線
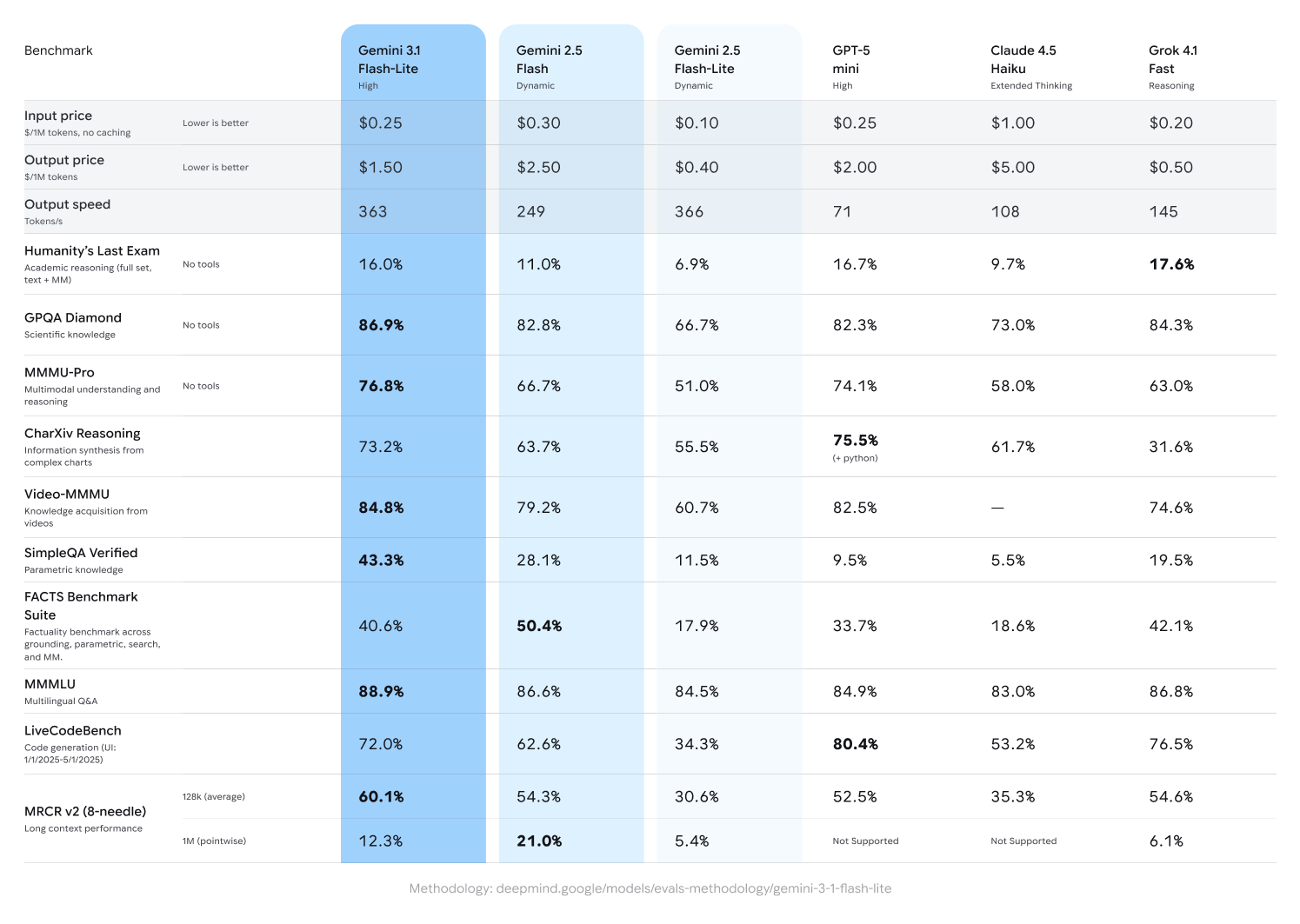
2026 年的 AI 競爭舞台上,Google 推出了極具侵略性的市場策略:每百萬 Input Token 0.25 美元、Output Token 1.50 美元,目前市面上僅有 Grok 4.1 Fast 的 0.2 / 0.5 能相提並論。
更令人矚目的是,Lite 版本並未削弱智能水準。根據基準測試數據,Gemini 3.1 Flash-Lite 在多項指標上表現亮眼,與 Gemini 2.5 Flash 相較:
- 反應速度大躍進:TTFT(首次代幣反應時間)提升 2.5 倍,輸出速度增加 45%,即時互動幾乎無感延遲
- 推理能力升級:在 Arena.ai 排行榜取得 1432 Elo 分數,GPQA Diamond(博士級推理)達成 86.9%
- 視覺理解強化:複雜圖像推理 MMMU Pro 取得 76.8% 成績
此結果說明 3.1 Flash-Lite 儘管定位為輕量版,其智能水準實際上已超越 Gemini 2.5 Flash,同時更快速、更便宜。
思考控制系統的靈活性
Gemini 3.1 Flash-Lite 同步導入了 Gemini 3 系列引入的 Thinking Levels(思考層級)參數,相當於 AI 的變速箱——能有效防止模型在處理簡單任務時過度運算,避免企業預算白白消耗。
透過 Google AI Studio 與 Vertex AI,開發者可精準設定:
- 高頻輕量任務(如內容審核):降低思考層級,換取超快反應與極低成本
- 複雜邏輯工作(如 UI 生成):提升層級讓 AI「深思熟慮再回應」,確保輸出精確度
此靈活度使 3.1 Flash-Lite 成為處理高吞吐量的理想首選,避免在簡單工作上浪費昂貴的運算資源。
應用實戰:高通量場景落地
Gemini 3.1 Flash-Lite 為大規模生產設計,適用於四大核心場景:
-
即時儀表板與 UI 生成:不限於返回 JSON 數據,它能根據實時天氣或動態資訊,秒速繪製精美的互動式介面
-
電商規模運營:能瞬間填充包含數百件商品、多種分類的電商框架,極大化前端開發與上架效率
-
SaaS 企業自動化:扮演數位行政角色,執行多步驟、跨系統的商業流程——從訂票、資訊彙整到數據同步,展現強大的指令遵循能力
-
高容量視覺分析:快速分析、篩選、分類龐大圖像與影片資料庫,對擁有豐富數位資產的品牌而言,是內容審核與組織的利器
企業佈局策略
當前市場形勢中,除了頂尖智能的旗艦模型,各廠商也在輕量版模型上明爭暗鬥。相較旗艦版有多元發展路線,輕量版往往角逐最高的 CP 值。
企業實際應用中,許多任務並不涉及深奧複雜的思考鏈,因此輕量版模型將成為基礎工作的優先選擇。在此背景下,Gemini 3.1 Flash-Lite $0.25 的定價幾乎構成壓倒性優勢。
EgentHub 提供企業級 AI Agent 管理平台,支援 GPT、Claude、Gemini、Grok 等主流模型的自由切換,並透過 MCP 串接功能,將 AI 無縫接上企業業務系統,真正實現 AI 落地應用。